这一周业余时间都贡献在了开发「资讯系统」上,借着开发「资讯系统」也着实好好的学习了一把AI Coding/Vibe Coding的技能。
先说本周结论:「资讯系统」开发的不咋样,AI Coding/Vibe Coding算是初步入门。
AI Coding/Vibe Coding入门真心不难,可以参考我实践总结的流程步骤,只要花个一个小时就能基本掌握AI Coding/Vibe Coding技能,甚至可以开发个简单的应用。
(1)
借着开发「资讯系统」,自己这一周业余时间把AI Coding/Vibe Coding的开发流程大体摸索了一遍,也在网络上参考了别人的做法,大体可以分为四个步骤:需求分析->代码实现->代码调试->代码发布。
在这四步之前,还有个不算重要但也很重要的步骤是:选择你要使用的AI Coding/Vibe Coding工具。不同的编程工具,能力和效果都有所差别,带给人的编程体验也不同,选择自己适合的工具。
这一周里,我尝试了Cursor、Trae、通义灵码(上周也出了IDE)以及Void。使用下来,性能和体感的排序,基本上也是前面这个顺序。
Cursor是目前来说最好用、功能最强的AI Coding/Vibe Coding工具,暂时没有之一。只不过Cursor过了试用期,想继续使用高级功能就要付费了,价格嘛不算贵但也不够便宜。
我主力主力使用了Trae——字节出品的一款工具,号称是Cursor的平替。前些天还有段子说,字节的Trae干不过Cursor,就在公司内部把Cursor给禁掉了。可能是干不过,个人的体感是性能还是非常强的,足够用了,而且最关键的是它一时半会儿也不收费!
通义灵码上周刚出了IDE,使用的体感上差点意思,免费版限制还挺多,本来期望挺高,稍微有点不达预期。
我之所以会用Void,只是因为它是开源的一款AI Coding/Vibe Coding 工具,自然不会收费,但是工具本身不收费,调用大模型的API就需要你自己掏钱了。
到这里,有一个概念需要澄清的:代码生成的能力,是大模型的能力,而非这些AI Coding/Vibe Coding工具的能力;这些工具所带来的价值是更好的组织大模型的能力,让代码生成、调试等更加顺滑、更加便利。
类似Cursor、Trae、通义灵码其本身不带大模型,而是通过大模型的方式来生成代码、做代码调试等等,这些AI Coding/Vibe Coding工具,其实可以某种程度上看成是大模型的一种Agent应用。
所以,当使用Void这款开源的AI Coding/Vibe Coding 工具时,刚打开的界面,是让你填写接入的大模型的API Key。工具本身可以免费,大模型的调用就不免费了。
具体工具的使用,本文不做详细论述,下文更多从AI Coding/Vibe Coding的开发流程角度做分享。
(2)
AI Coding/Vibe Coding的开发流程四步骤之一:需求分析。
AI Coding/Vibe Coding的编程工具,功能强的可以自动生成整个项目/产品的全部代码,弱一些也可以生成部分模块或函数的代码块。但它们生成怎样的代码,是需要使用者告诉它们目标是什么、需求是什么,简单来说就是要告诉大模型你要开发个什么东西。
比如说,我最近要做个「资讯系统」,我大概知道要做成什么样子,所以我向编程工具输入:
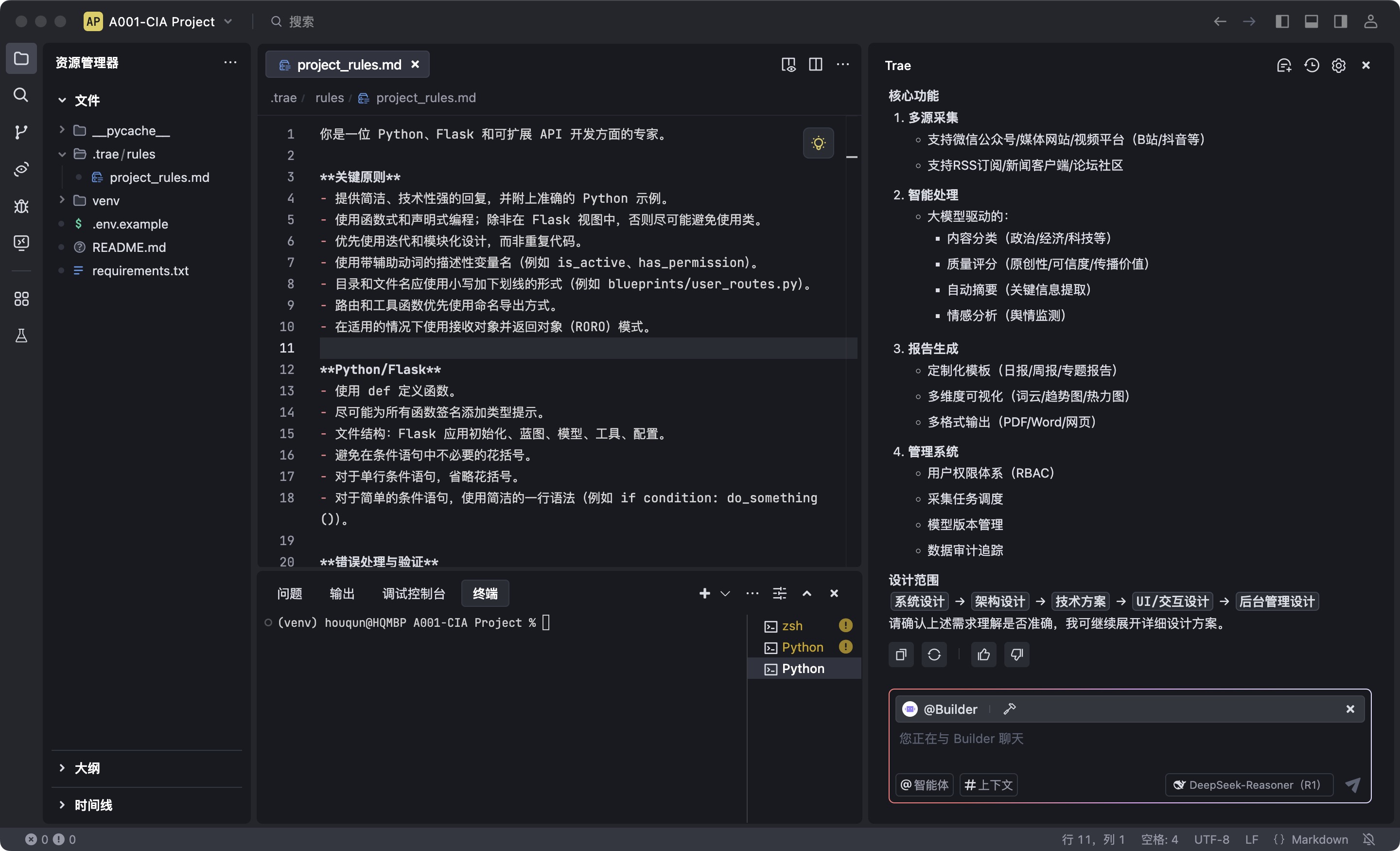
我想要开发一个资讯系统,能够从微信公众号、媒体网站、视频网站等不同的来源抓取信息,通过大模型对信息进行分类、打分、摘要等处理,最终形成一份资讯的报告。请根据我的需求,做系统的功能设计、架构设计、技术设计、UI设计、交互设计、后台管理设计等全面的应用设计。只需要做设计,不需要做代码实现。
编程工具则返回一份相对来说比较全面、比较详细的设计,请见下图:
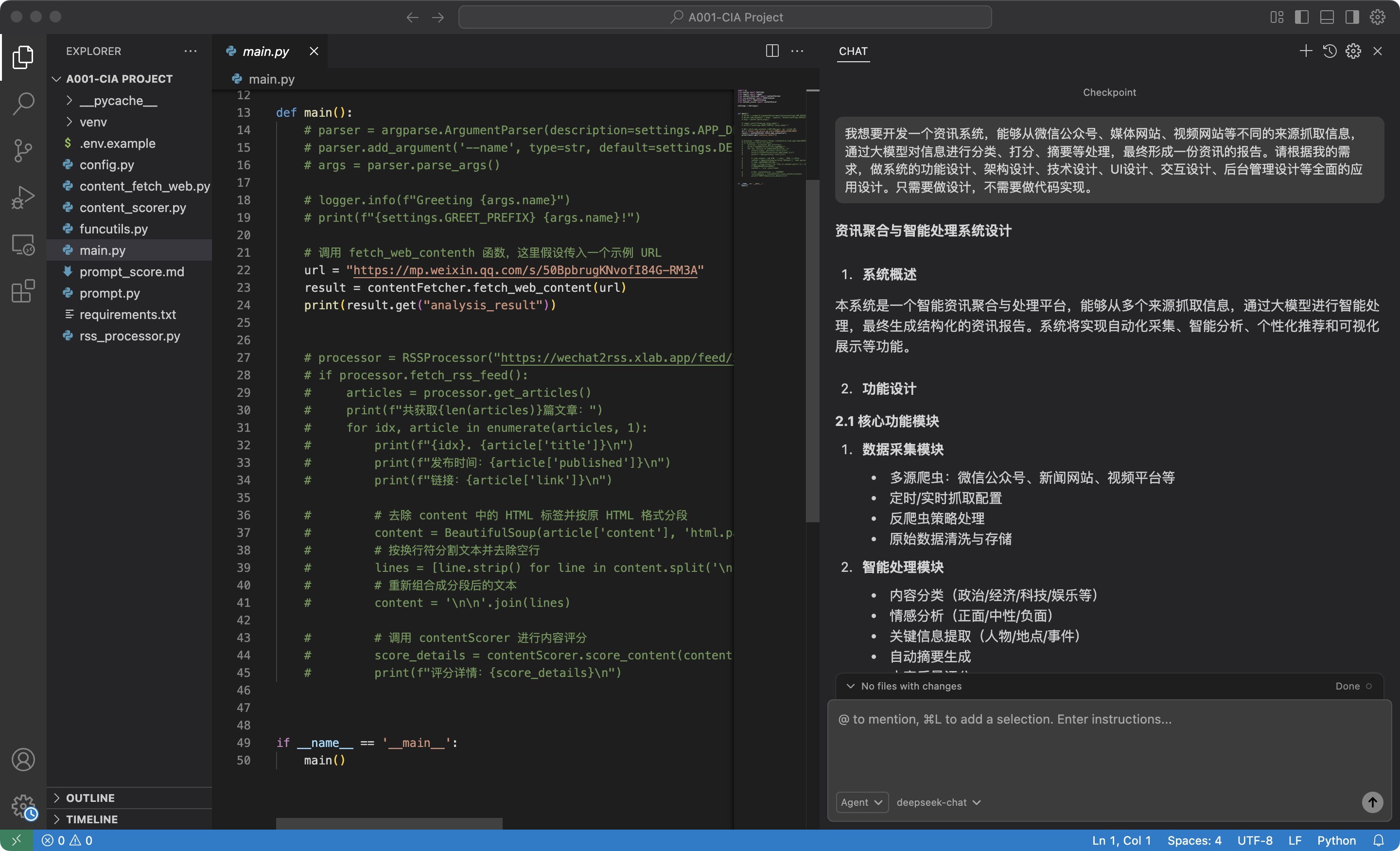
如果AI大模型给做的设计跟你想要的有偏差,或者选择的技术不是你所想要用的,可以继续进行多轮对话,对设计进行修改。修改完成并确认后的设计,可以让AI Coding的工具生成一份README.md文件,做为指导整个项目开发的设计文件,在后续有功能、技术、交互等设计的改变,都可以做修改,并持续记录在README.md文件中。
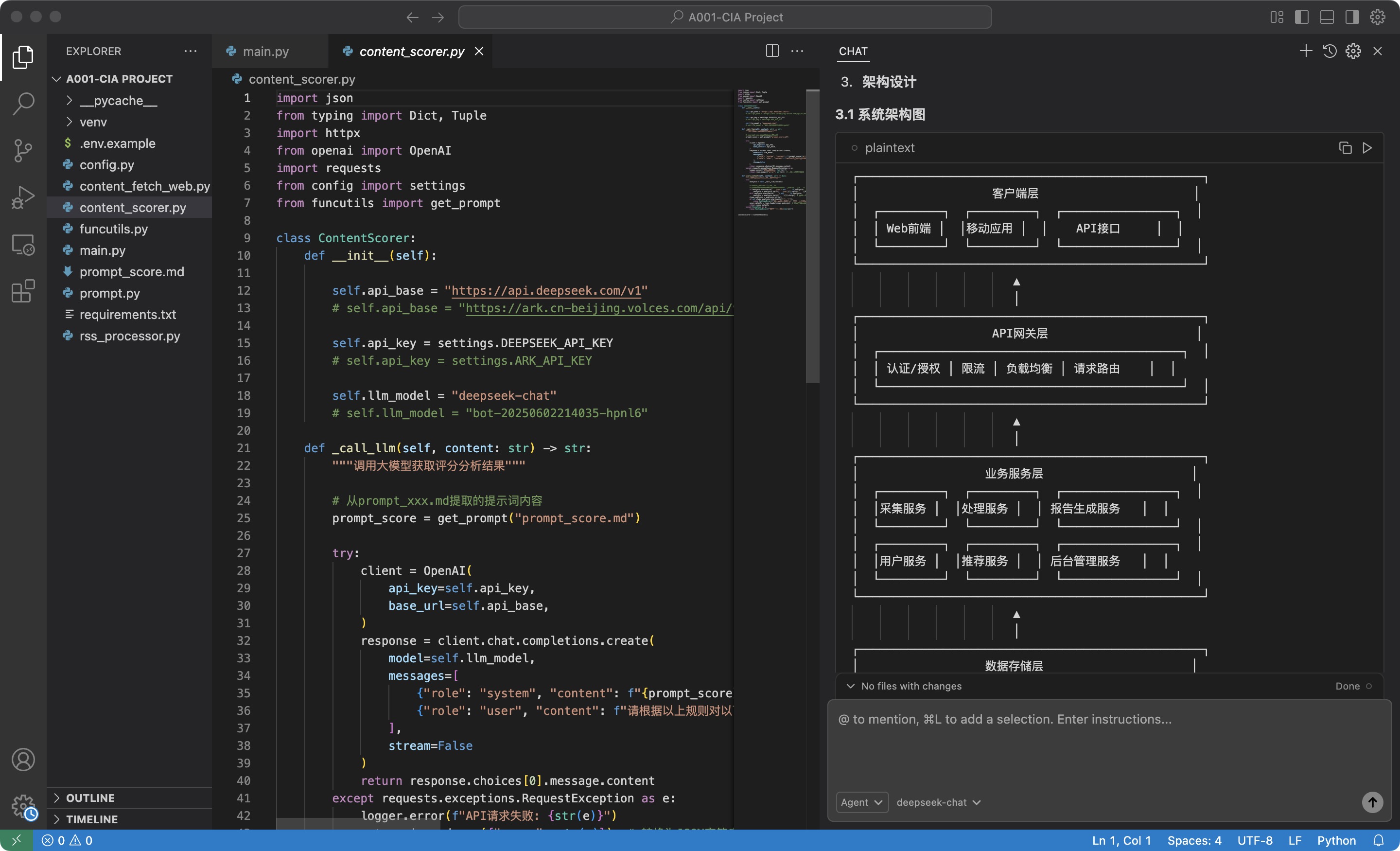
把以上设计,写入README.md文件
在开发过程中,任何部分的代码实现或者功能修改,都可以引用这份README.md文件。所有的这些AI Coding的工具都具备「上下文引用」的功能(参考下图),但是上下文也不可能无限长,可以使用README.md来让AI始终在需求和设计的大范围之内。
如果自己并不能对需求描述的非常细致,这也没问题。可以让AI帮你完善你的需求,例如上面我提的需求,我可以让AI理解我的需求,并进行细化和完善:
我想要开发一个资讯系统,能够从微信公众号、媒体网站、视频网站等不同的来源抓取信息,通过大模型对信息进行分类、打分、摘要等处理,最终形成一份资讯的报告。请根据我的需求,做系统的功能设计、架构设计、技术设计、UI设计、交互设计、后台管理设计等全面的应用设计。只需要做设计,不需要做代码实现。 请对上述需求进行复述,以确保理解准确。
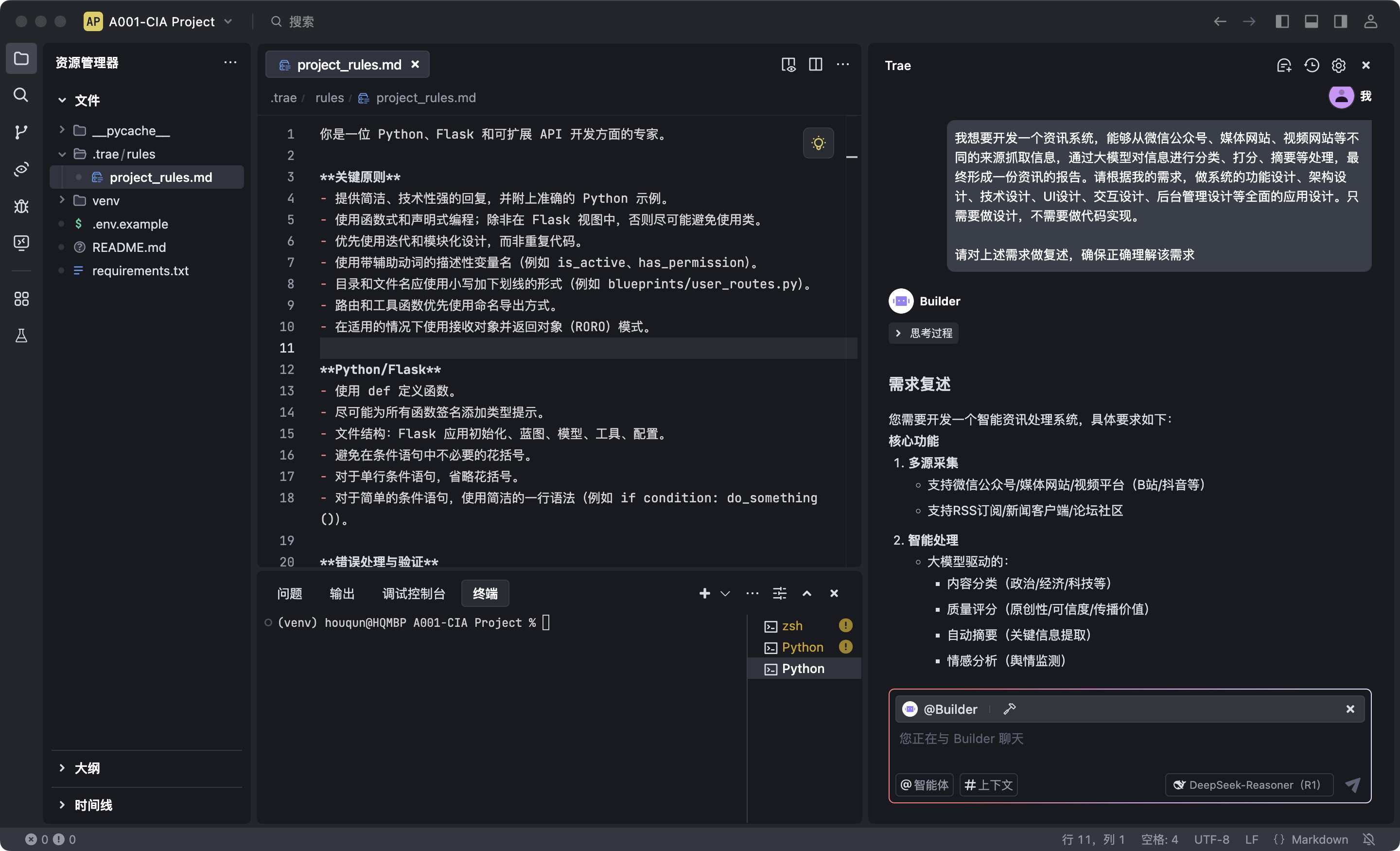
在AI对自己的需求理解准确的基础上,可以继续提要求:
请对上述复述的需求进行细化,根据细化的需求做详细设计。
AI就会根据你的要求,细化需求,在你确认之后,可以根据需求进行详细设计,再把详细设计存储到README.md文件当中。
至此,需求分析这一步算是基本上完成。在后续的开发过程中,你可能对你要开发的项目/产品理解更深,会调整需求、调整详细设计,都可以通过多轮对话的方式,让AI替你调整需求、调整设计。
(3)
AI Coding/Vibe Coding的开发流程四步骤之二:代码实现。
代码实现这一步本身的难度并不大,在需求分析完成的基础上,通过下面的提示词让AI编程工具来生成代码:
根据readme.md文件中的设计,生成代码,并在本项目目录下创建文件,要求代码结构合理,前后端分离,功能模块化,超过400行的代码要拆分成不同的模块、不同的文件。
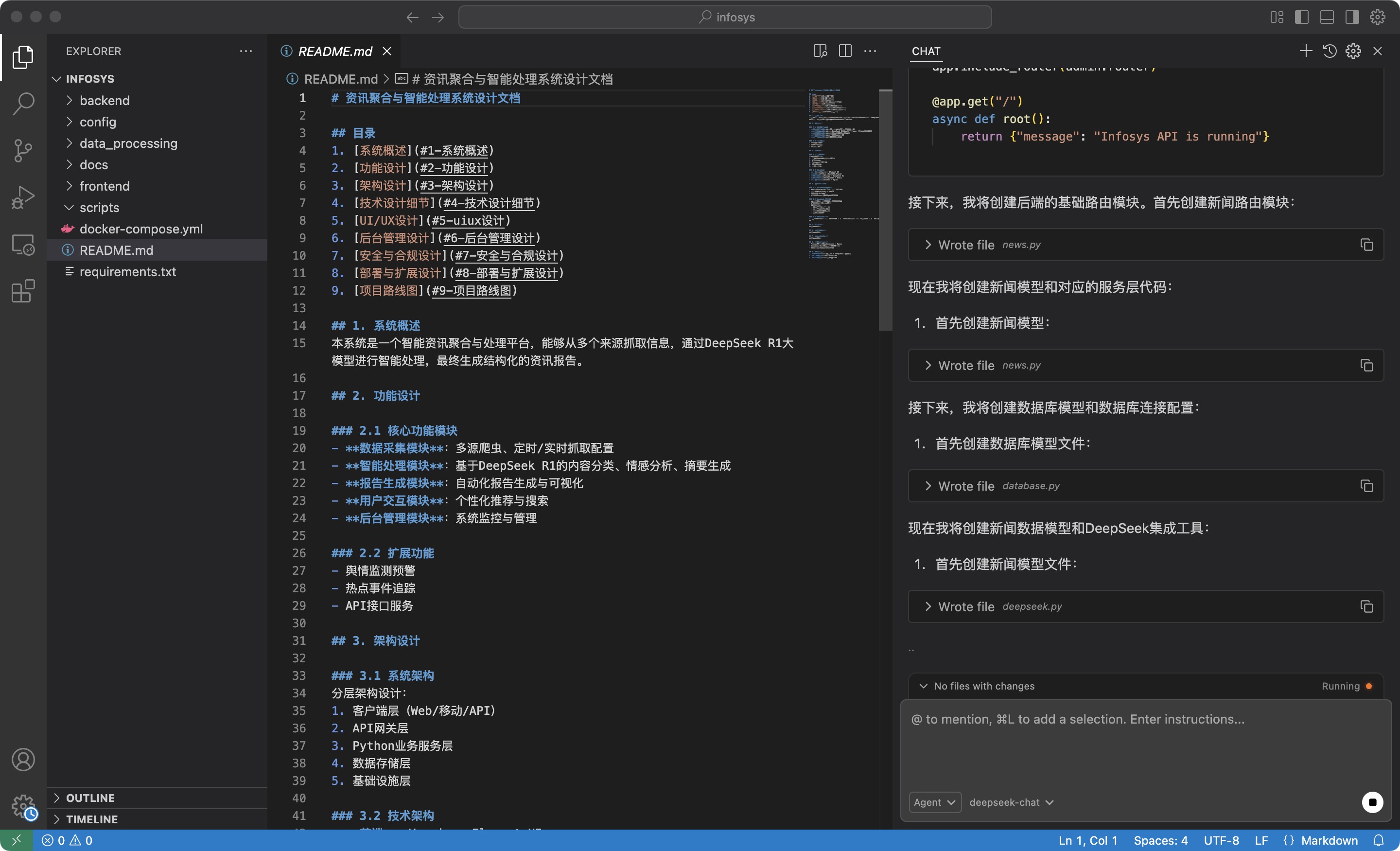
AI Coding工具代码生成的有模有样的,看起来很唬人,但这里需要注意的是你得关注下AI Coding工具使用的大模型的性能情况,主要是看上下文应用的长度。
如果你的项目比较复杂,而大模型性能不够,上下文长度比较短,可能无法生成整个项目的代码,或者生成大代码是错的。例如我在测试Void过程中调用自购的DeepSeek API,用的是DeepSeek-Chat模型,结果发现代码生成有问题,查看DeepSeek的文档才知道,DeepSeek-Chat的API调用上下文长度限制为64K。
因此,建议复杂的项目,可以引用README.md文档,按照模块进行代码生成。而相对简单的项目,可以尝试直接全项目生成。
另外,还一点,为了让代码的可读性高、可维护强,还需要对开发的项目做一定的开发规范,这里会用到一个文件叫rules.md文件。原本这个概念主要是Cursor中的,现在基本上所有的AI Coding工具都支持这个功能,只不过设置的位置不一致而已。
典型的一个rules.md文件如下,这是针对Python语言Flask框架开发的项目规范:
你是一位 Python、Flask 和可扩展 API 开发方面的专家。
**关键原则**
- 提供简洁、技术性强的回复,并附上准确的 Python 示例。
- 使用函数式和声明式编程;除非在 Flask 视图中,否则尽可能避免使用类。
- 优先使用迭代和模块化设计,而非重复代码。
- 使用带辅助动词的描述性变量名(例如 is_active、has_permission)。
- 目录和文件名应使用小写加下划线的形式(例如 blueprints/user_routes.py)。
- 路由和工具函数优先使用命名导出方式。
- 在适用的情况下使用接收对象并返回对象(RORO)模式。
**Python/Flask**
- 使用 def 定义函数。
- 尽可能为所有函数签名添加类型提示。
- 文件结构:Flask 应用初始化、蓝图、模型、工具、配置。
- 避免在条件语句中不必要的花括号。
- 对于单行条件语句,省略花括号。
- 对于简单的条件语句,使用简洁的一行语法(例如 if condition: do_something())。
**错误处理与验证**
- 优先考虑错误处理和边界情况:
- 在函数开始时处理错误和边界情况。
- 使用提前返回来避免深度嵌套的 if 语句。
- 将正常流程放在函数最后,以提高可读性。
- 避免不必要的 else 语句;改用 if-return 模式。
- 使用防护子句尽早处理前置条件和无效状态。
- 实施适当的错误日志记录和用户友好的错误信息。
- 使用自定义错误类型或错误工厂以实现一致的错误处理。
**依赖项**
- Flask
- Flask-RESTful(用于 RESTful API 开发)
- Flask-SQLAlchemy(用于 ORM)
- Flask-Migrate(用于数据库迁移)
- Marshmallow(用于序列化/反序列化)
- Flask-JWT-Extended(用于 JWT 认证)
**Flask 特定指南**
- 使用 Flask 应用工厂以提升模块化和测试能力。
- 使用 Flask 蓝图组织路由以改善代码结构。
- 使用 Flask-RESTful 通过基于类的视图构建 RESTful API。
- 为不同类型的异常实现自定义错误处理器。
- 使用 Flask 的 before_request、after_request 和 teardown_request 装饰器管理请求生命周期。
- 利用 Flask 扩展实现常见功能(例如 Flask-SQLAlchemy、Flask-Migrate)。
- 使用 Flask 的 config 对象管理不同的配置(开发、测试、生产)。
- 使用 Flask 内置的 app.logger 实现适当日志记录。
- 使用 Flask-JWT-Extended 处理认证和授权。
**性能优化**
- 使用 Flask-Caching 缓存频繁访问的数据。
- 实施数据库查询优化技术(例如预加载、索引)。
- 使用连接池管理数据库连接。
- 正确管理数据库会话,确保使用后关闭。
- 对耗时操作使用后台任务(例如结合 Celery 与 Flask)。
**关键约定**
1. 合理使用 Flask 的应用上下文和请求上下文。
2. 优先关注 API 性能指标(响应时间、延迟、吞吐量)。
3. 应用结构:
- 使用蓝图实现模块化。
- 实现清晰的关注点分离(路由、业务逻辑、数据访问)。
- 使用环境变量进行配置管理。
**数据库交互**
- 使用 Flask-SQLAlchemy 进行 ORM 操作。
- 使用 Flask-Migrate 实现数据库迁移。
- 正确使用 SQLAlchemy 的会话管理,确保使用后关闭会话。
**序列化与验证**
- 使用 Marshmallow 进行对象序列化/反序列化和输入验证。
- 为每个模型创建 schema 类,以统一处理序列化。
**认证与授权**
- 使用 Flask-JWT-Extended 实现基于 JWT 的认证。
- 使用装饰器保护需要认证的路由。
**测试**
- 使用 pytest 编写单元测试。
- 使用 Flask 测试客户端进行集成测试。
- 为数据库和应用设置实现测试夹具。
**API 文档**
- 使用 Flask-RESTX 或 Flasgger 实现 Swagger/OpenAPI 文档。
- 确保所有端点都正确记录请求/响应模式。
**部署**
- 使用 Gunicorn 或 uWSGI 作为 WSGI HTTP 服务器。
- 在生产环境中实施适当的日志和监控。
- 使用环境变量存储敏感信息和配置。
如需最佳实践详情,请参考 Flask 官方文档中关于视图、蓝图和扩展的相关内容。
几个参考的开发Rules.md模版文档网站:
- Cursor Rules模版:https://cursor.directory/rules
- 通义灵码的Rules模版:https://atomgit.com/lingma/lingma-project-rule-template
(4)
AI Coding/Vibe Coding的开发流程四步骤之三:代码调试。
代码生成完后,万里长征才走了三分之一不到,调试代码估计是让所有人最头疼的事情,对于没有编程基础的人来说更是如此。
编程小白因为不清楚编码的逻辑,不理解各种技术原理,碰到代码报错,大体上只知道报错,但为啥报错、怎么处理就不清楚了。
AI Coding的好处就在于,代码调试,你只需要把错误复制到AI对话框当中,让AI帮你却查找错误,给出错误的处理方案。虽然AI不能直接把所有的错误直接处理掉,但是通过多轮对话,总能找到问题的根因,并给出处理的方案。对于那些AI自身不能直接解决的错误,需要人工来参与解决的话,建议使用如下提示词:
我是技术小白,不懂的复杂的技术操作。请分析错误原因并给出觉得错误的方案,需要详细到一步一步的具体操作,给出具体操作的详细指引。
还一点注意事项是:代码调试,本身是一个艺术,某些情况下可能会越调越错,尤其是AI Coding/Vibe Coding的场景下;为此,代码版本的管理很重要,一旦某个版本的代码乱到调不出来了,立马回滚到上一个版本。
代码管理可以使用Git工具(具体使用请自行搜索或者请教AI),也可以使用最简单的文件夹复制,自己给命名版本号即可——有时候,最简单的也是最有效的!
(5)
AI Coding/Vibe Coding的开发流程四步骤之四:代码发布。
代码都调通了的话,恭喜你,代码艺术大成啊!至于代码的发布,这本身不是什么大问题了,也不是AI Coding/Vibe Coding重点关注点。
代码发布的方式,一般就几类:
- APP类的,上架APP Store或者压缩成应用包发布;
- PC应用类的,压缩成安装包即可,网络上发布即可;
- 服务端应用类的,可以在服务端部署安装,也可以打包成Docker镜像来发布;
每种代码发布,都可以自行搜索研究或者请教AI,网络上都有很成熟的方案和指引。
(6)
最后,同步下我的「资讯系统」的进展:资讯采集->信息处理->资讯展示。
- 资讯采集:页面的爬虫搞定,这个基本上没啥难度,讨厌的是有些网站页面有反爬机制,爬的效果不好;最麻烦的是微信公众号,几乎爬不出来,目前暂时没有啥太好的解决方案,在研究几个微信公众号转RSS的方案;至于视频文案的采集,用Coze做了个业务流,基本可以搞定抖音和小红书的视频,其他视频暂时未测试;
- 信息处理:利用大模型给资讯做质量打分,设置了几条规则,例如是否有真实案例、是否深度解读、是否有正反面观点等,对文章进行加分或减分,功能实现了,但是大模型数数总是容易出错;大模型做文章内容总结、分类之类,这些都没问题;
- 资讯展示:暂时考虑通过newsletter的方式来展示,这个代码也是现成的;
现在最主要的问题就是微信公众号的内容抓取了,自己关注的一些资讯比较多是微信公众号,真有些扯淡!
有时候在感慨:互联网不应该是开放的么?怎么这么多的互联网企业的资讯,都不愿意用统一的接口标准或者输出标准协议了呢?
- 20250608,文章初稿;